Nimbostratus ?
Nimbostratus is a reactive data-fetching and client-side cache management library built on top of Cloud Firestore.
The Cloud Firestore client API for Flutter is great at fetching and streaming documents. Nimbostratus extends that API to include some additional features:
- APIs for reading, writing and subscribing to documents changes on the client using the Nimbostratus in-memory cache.
- New data fetching policies like cache-first and cache-and-server to implement common data fetching practices for responsive UIs.
- Support for optimistic updates through cache-write policies.
Usage
Reading documents ?
import 'package:nimbostratus/nimbostratus.dart';
final snap = await Nimbostratus.instance.getDocument(
FirebaseFirestore.instance.collection('users').doc('alice'),
fetchPolicy: GetFetchPolicy.cacheFirst,
);
In this example, we request to read a Firestore document from the cache first, falling back to the server if it is unavailable. There are a few handly fetch policies to choose from which you can look at here.
Streaming documents ?
Documents can similarly be streamed from the cache, server, or a combination of both:
final documentStream = Nimbostratus.instance
.streamDocument(
FirebaseFirestore.instance.collection('users').doc('user-1'),
fetchPolicy: StreamFetchPolicy.cacheAndServer,
).listen((snap) {
print(snap.data());
// { 'id': 'user-1', 'name': 'Anakin Skywalker' }
// Later when the document changes on the server:
// { 'id': 'user-1', 'name': 'Darth Vader' }
});
In this case, we’re streaming the document users/user-1 from both the cache and the server. A fetch policy like this can be valuable since data can be eagerly returned from the cache in order to create a zippy user experience, while maintaining a subscription to changes from the server in the future.
Streamed documents will also update when changes are made to the cache. In the example below, we can manually update a value in the in-memory cache, causing all of the places across the client that are streaming the document to update:
final docRef = FirebaseFirestore.instance.collection('users').doc('user-1');
final documentStream = Nimbostratus.instance
.streamDocument(
docRef,
fetchPolicy: StreamFetchPolicy.cacheAndServer,
).listen((snap) {
print(snap.data());
// { 'id': 'user-1', 'name': 'Anakin Skywalker' }
// { 'id': 'user-1', 'name': 'Darth Vader' }
});
await NimbostratusInstance.updateDocument(
docRef,
{ 'name': 'Darth Vader' }
writePolicy: WritePolicy.cacheOnly,
);
Executing and reacting to client-side cache changes is an intentional gap in the included feature set of the cloud_firestore, since it is meant to function as a relatively simple document-fetching layer rather than a document management layer. Nimbostratus aims to fill that gap and provide functionality similar to other data fetching libraries that have more extensive client APIs.
Querying documents ?
Querying for documents follows a similar pattern:
final stream = Nimbostratus.instance
.streamDocuments(
store.collection('users').where('first_name', isEqualTo: 'Ben'),
fetchPolicy: StreamFetchPolicy.serverFirst,
).listen((snap) {
print(snap.data());
// [
// { 'id': 'user-1', 'first_name': 'Ben', 'last_name': 'Kenobi', 'side': 'light' },
// { 'id': 'user-2', 'first_name': 'Ben', 'last_name': 'Solo', 'side': 'light' }
// ]
});
With the serverFirst policy shown above, data will first be delivered to the stream from the server once and then the stream will listen to any changes to the cached data. When a later cache update occurs like this:
await NimbostratusInstance.updateDocument(
store.collection('users').doc('user-2'),
{ 'side': 'dark' }
writePolicy: WritePolicy.cacheAndServer,
);
Since the stream is subscribed to any changes to documents user-1 and user-2 with a cacheAndServer write policy, the stream will immediately receive the updated query snapshot from the cache:
// [
// { 'id': 'user-1', 'first_name': 'Ben', 'last_name': 'Kenobi', 'side': 'light' },
// { 'id': 'user-2', 'first_name': 'Ben', 'last_name': 'Solo', 'side': 'dark' }
// ]
and then later emit another value based on the server response if it differs from the initial cached response, such as if another field had been added to the document on the server since we last queried for it:
// [
// { 'id': 'user-1', 'first_name': 'Ben', 'last_name': 'Kenobi', 'side': 'light' },
// { 'id': 'user-2', 'first_name': 'Ben', 'last_name': 'Solo', 'side': 'dark', 'relationship_status: 'complicated' }
// ]
Optimistic updates ⚡️
The cacheAndServer policy in the example above is an optimistic write policy. The update is first written to the cache optimistically and then if the server response then fails, the cached change will be rolled back to the most up-to-date value. Optimistic updates
make it possible to present a user with an immediately updated value and make an application feel live and zippy, while making sure that if something goes wrong, the experience can be rolled back to a consistent server state.
Batch updates ?
Firestore supports batching of multiple document updates together with the batch API. We can take advantage of the Nimbostratus data fetching and writing features when batching using the batchUpdateDocuments API:
await Nimbostratus.instance.batchUpdateDocuments((batch) async {
await batch.update(
store.collection('users').doc('darth_maul'),
{ "alive": false },
writePolicy: WritePolicy.cacheAndServer,
);
await batch.update(
store.collection('users').doc('qui_gon'),
{ "alive": false },
writePolicy: WritePolicy.cacheAndServer,
);
await batch.commit();
});
In this example, we’re using the cacheAndServer policy again to optimistically apply our cache updates. The difference when using Firestore batches is that the server updates aren’t finalized until the commit() call succeeds. If the server response fails and an exception is thrown by commit(), the optimistic cached changes will be rolled back as well.
There are other cases where you still want to perform optimistic updates in the cache for remote updates that aren’t made through Firestore, such as updating a document in Firestore indirectly through a Cloud Function:
await Nimbostratus.instance.batchUpdateDocuments((batch) async {
await batch.update(
store.collection('users').doc('darth_maul'),
{ "alive": false },
writePolicy: WritePolicy.cacheOnly,
);
await batch.update(
store.collection('users').doc('qui_gon'),
{ "alive": false },
writePolicy: WritePolicy.cacheOnly,
);
await FirebaseFunctions.instance.httpsCallable('finish_episode_1').call();
});
In this example, we optimistically update documents in the cache before making the call the Cloud Function. If the call fails and throws an error, the optimistic cache updates will automatically be rolled back. If the batch update function finishes without throwing an error, then the optimistic updates are committed and made permanent.
Gotchas
-
The cache updates made on the client are in-memory. The Firestore cache does not support direct writing to it, so instead the Nimbostratus caching layer sits on top of the Firestore persistent cache in memory. Restarting your application will not persist your cached changes, you’ll need to make server changes that Firestore will then persist in its separate cache.
-
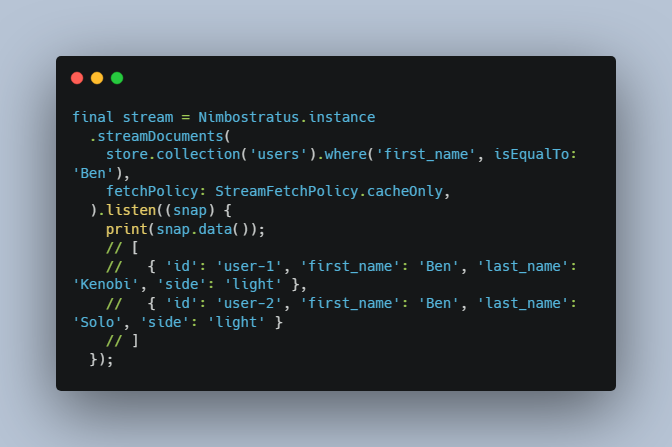
Queries that stream documents only from the cache such as when using
StreamFetchPolicy.cacheOnlywill only update in response to changes to their current documents, not new documents that are added. If for example, we have a query like this:
final stream = Nimbostratus.instance
.streamDocuments(
store.collection('users').where('first_name', isEqualTo: 'Ben'),
fetchPolicy: StreamFetchPolicy.cacheOnly,
).listen((snap) {
print(snap.data());
// [
// { 'id': 'user-1', 'first_name': 'Ben', 'last_name': 'Kenobi', 'side': 'light' },
// { 'id': 'user-2', 'first_name': 'Ben', 'last_name': 'Solo', 'side': 'light' }
// ]
});
and then at a later time, a new document with first_name ‘Ben’ is added in the cache, this query will not update with that new user, since it does not know that they should be included. The opposite is true if we update user-2 to first_name: Han. The query will still re-emit the user-2 on the stream, even though they no longer satisfy the query’s filters. In order to stream documents that re-evaluate the query, you will need to use a server policy like StreamFetchPolicy.cacheAndServer or StreamFetchPolicy.serverOnly.
- Cache updates currently do not merge data the same as on the server. The set and update APIs from Firestore support some advanced data merging options for document fields. When we make an update to the cache like this:
await NimbostratusInstance.setDocument(
FirebaseFirestore.instance.collection('users').doc('user-1'),
{ 'name': 'Darth Vader', ...nestedFields }
options: SetOptions(
mergeFields: ['name', 'nestedFields1.nestedFields2...']
)
writePolicy: WritePolicy.cacheAndServer,
);
The first cache update uses just a simple merge of the maps and not making the more advanced nested field path changes that will subsequently be reflected in the server response. When the server response comes back, the cache will also be updated to that fully merged server update. This is currently a TODO that if anyone wants to work on to achieve parity with the server update feel free to reach out.